
Heart failure affects about 6.2 million people in the US, yet there is no treatment for the most common form of the disease: heart failure with preserved ejection fraction (HFpEF). Late-stage clinical trial failures are largely to blame for the lack of effective treatment options for patients with HFpEF, and poor five-year survival rates make this an area of great unmet need.
“It’s not just one disease,” says Dr. Irene Blat, PhD, senior director of data products and analytics, Genuity Science. “There are different subtypes of heart failure that have different clinical presentations.”
New advances in heart failure genomics are helping to address this challenge. Experts from Servier and Genuity Science recently spoke on a webinar about using genomics data to drive drug development in heart failure and identify new targets for novel therapeutics. Watch this on-demand webinar to hear from these experts.
HFrEF vs. HFpEF
Heart failure patients can be categorized into three groups based on a measurement of how much blood is pumped out of the heart through the left ventricle after each muscle contraction, known as ejection fraction (EF). While normal EF measurements lie between 50 and 70 percent, patients with heart failure show a range of clinically relevant values.
Patients with an EF value of <40 percent are categorized as having heart failure with reduced ejection fraction (HFrEF). Those with slightly higher EF values of 40 to 49 percent — but still below normal — are said to have heart failure with mid-range ejection fraction (HFmEF). However, the bulk of heart failure patients are categorized as HFpEF since their ejection fraction values are ≥50 percent and, therefore, fall within the normal range.
This phenotypic marker often hints at the underlying mechanisms contributing to heart failure and can help clinicians determine the most appropriate course of treatment. While heart failure has a heritable component, there are different risk factors for HFrEF compared to HFpEF.
Males, individuals who smoke and those who have previously experienced myocardial infarction have a higher risk of HFrEF, with hyperlipidemia and diabetes playing a smaller role in disease susceptibility. HFpEF more often affects women, with diabetes and hyperlipidemia being larger risk factors, along with obesity and hypertension.
Current Treatments for HFpEF and HFrEF
Like other disease areas, the heterogeneity of heart failure makes it difficult to develop effective therapeutics that will work for patients in each of the subtypes. Ivabradine, angiotensin-converting enzyme (ACE) inhibitors, angiotensin receptor blockers (ARB), β-blockers, mineralocorticoid receptor antagonists (MRAs) and angiotensin receptor neprilysin inhibitors (ARNI) are all used to treat patients with HFrEF.
However, these drugs have shown limited effectiveness in treating HFpEF. Dr. Benoit Tyl, MD, FESC, medical and scientific director, cardiology at Servier, says that the disconnect between correlation and causality in cardiovascular disease trials is partially responsible for the lack of approved HFpEF therapies.
“A lack of efficacy is the greatest reason for clinical trial failures, especially in Phase II and Phase III,” says Dr. Tyl. “And most of this lack of efficacy is due to lack of causality between the heart target and the disease.”
For example, there is a positive correlation between heart rate and risk of coronary artery disease, the most common form of heart disease and a precursor to heart failure. As heart rate increases, so too does the likelihood of experiencing ischemic episodes. However, the SIGNIFY trial involving the heart-rate-reducing drug ivabradine failed to show a change in cardiovascular deaths or non-fatal myocardial infarction in patients with coronary artery disease.
This suggests that there may be a confounding factor that has an effect on both heart rate and coronary artery disease, as opposed to increased heart rate having a causative effect on the outcome. The reverse could also be true whereby the development of coronary artery disease may impact heart rate.
Case Study: Genomic Approaches in Coronary Artery Disease Drug Development
A 2015 study published in Nature Genetics found that the availability of human genetic data made investigational drugs twice as likely to pass pivotal trials and eventually be approved. This conclusion was later confirmed in a 2019 paper published in PLOS Genetics, reaffirming the power of genomic tools to uncover genetic disease associations and validate drug targets.
Drug target validation using Mendelian randomization (MR) combined with data from genome-wide association studies (GWAS) can be a useful approach in determining whether certain genetic variants have a causative effect on heart failure outcomes (Figure 1).
In fact, this approach was used to identify genetic variants associated with hypertension and determine whether high blood pressure is a causative factor for coronary artery disease. In their 2013 paper published in the journal Hypertension, an international team of researchers describe how they performed a GWAS study using data from over 22,000 individuals with coronary artery disease and over 64,000 controls.
From a total of 30 single-nucleotide polymorphisms (SNPs) in genes previously identified as being associated with blood pressure, many had a relatively neutral effect on the risk of coronary artery disease. But interestingly, a variant of the SH2B3 gene was linked with an increased risk of the disease, while a variant of the ATP2B1 gene actually decreased risk. From this, the study authors were able to conclude that high blood pressure has a causative effect on the risk of coronary artery disease, and validate the identified associated genes as useful drug targets.
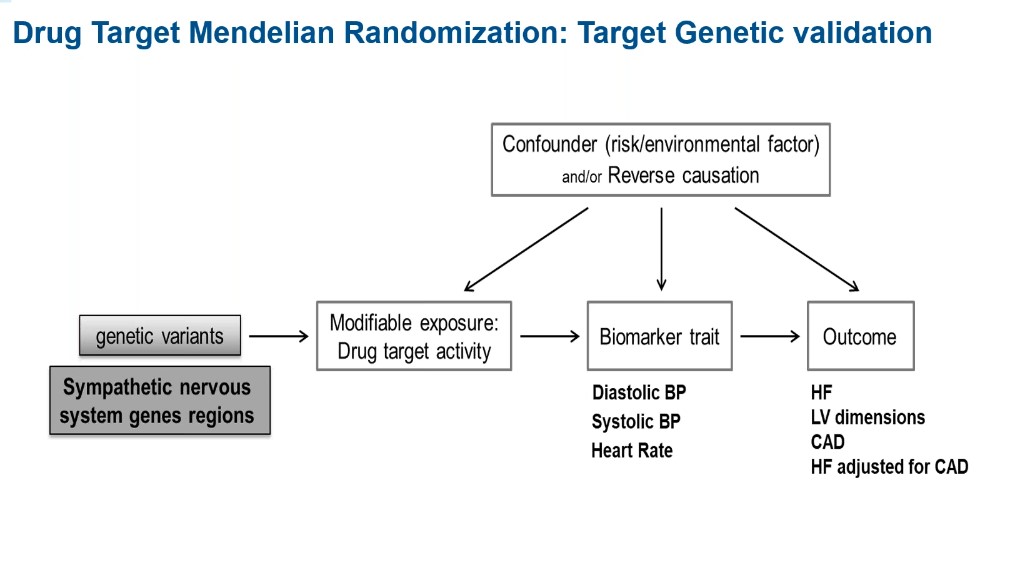
Figure 1: The use of Mendelian randomization to validate genetic drug targets.
Since it’s not always possible to measure the direct effect of a gene, biomarkers are often used to measure its effect on a given outcome.
“If your drug target is a gene that codes for a target known to modulate blood pressure, you can use blood pressure to select the functional variant of this target gene,” says Dr. Tyl. “Such a drug target MR has been shown to work well in coronary artery disease.”
A particularly poignant example of this is the development of darapladib, a drug shown to decrease lipoprotein-associated phospholipase A2 (Lp-PLA2), an enzyme associated with an increased risk of coronary artery disease. An MR study was performed concurrently with randomized clinical trials of darapladib which found that variants of the PLA2G7 gene that encodes for Lp-PLA2 did not show causality with cardiovascular risk factors.
The results of the drug-target MR were consistent with those from the trial investigating darapladib, which found that the drug did not reduce the risk of cardiovascular death, myocardial infarction or stroke in patients with stable coronary artery disease, despite the fact that it did lower levels of Lp-PLA2.
Drug Target MR in Heart Failure
“We questioned ourselves and wondered whether such a method could be used for heart failure,” explains Dr. Tyl. “So we decided to launch the pilot MR drug study with the objective to explore the causality of the genes involved in the sympathetic nervous system in heart failure.”
Dr. Tyl says that the genes of the sympathetic nervous system were chosen based on how well characterized one of the genes is in terms of its role in heart failure. Of the nine genes involved in sympathetic nervous system changes in heart failure (Figure 2), the ADRB1 gene is the most well-known as it encodes for the beta-1 adrenergic receptor.
Beta-blockers are commonly prescribed drugs to lower blood pressure in those at risk of heart failure. According to Dr. Tyl, inclusion of ADRB1 gene variants acts as somewhat of a positive control for the study since beta-blockers have such a well-demonstrated effect on decreasing the risk of heart failure and other cardiovascular diseases.
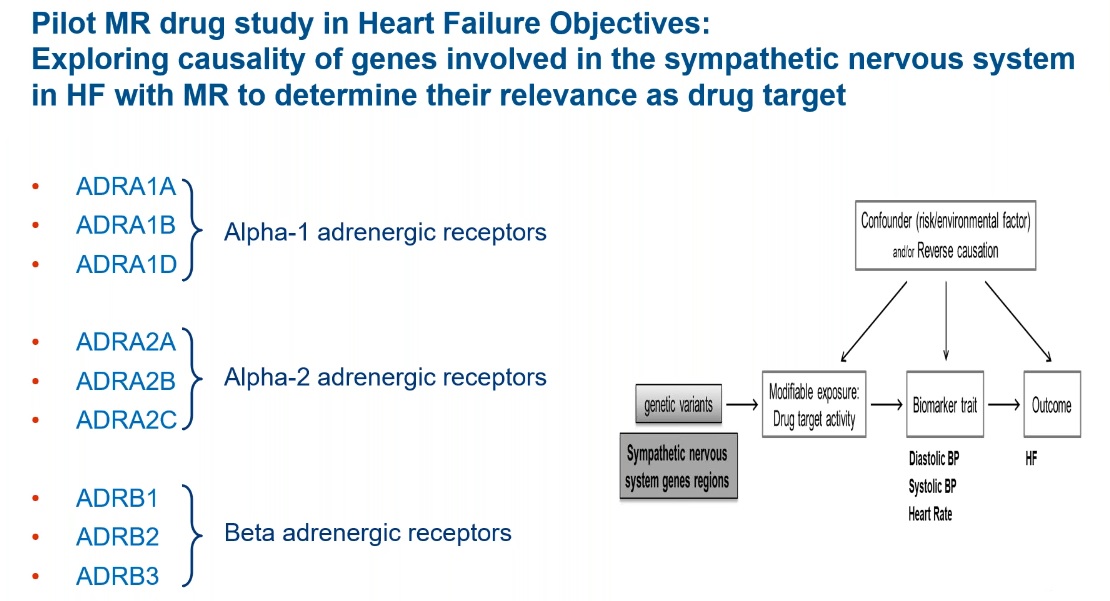
Figure 2: Using drug-target MR to validate sympathetic nervous system genes involved in heart failure.
“The most complex and lengthy part of the drug target MR lies within the building of the genetic tools,” says Dr. Tyl. “We started by selecting a list of candidate variants associated with each gene.”
While Dr. Tyl says that the simplest approach would have been to look for variants both within the gene and in the non-coding regions 200 kb on either side of the sequence, this would not have worked for all nine genes included in the pilot program. For example, the sequence environment around the ADRA2B gene contains many other nearby genes, so a simple approach to SNP selection would generate spurious results.
Instead, the team decided to target their search to the gene, promoter and enhancer regions, based on sequences from the GeneHancer database. The group at Servier made use of data from two GWAS on blood pressure and heart failure: an exposure GWAS from 2018 involving 750,000 participants, and the recently published HERMES outcome GWAS. Since both studies involved participants from the UK Biobank, Dr. Tyl and colleagues used a version of the HERMES data which excluded those from the UK cohort to avoid overlapping data.
They were successful at identifying at least one functional variant for four of the nine sympathetic nervous system genes included in the study, one of which (ADRB1) had nine variants (α1 A, B, D; α2 A, B, C; and ß 1, 2, 3). Variants with effects on either systolic or diastolic blood pressure were investigated; however, more variants overall were identified for the latter biomarker, making it their primary analysis.
“We were able to confirm using our method the well-known protective effect of a lower β1 activity on the risk of heart failure,” says Dr. Tyl, referencing a paper published last year in Circulation. “We studied a similar protective effect of lower α1A activity. Counterintuitively, we found that lower α2B activity was associated with an increased risk of heart failure. And we found no evidence for a causal risk of β2 activity in heart failure.”
Benefits and Limitations of Drug-Target MR
Despite the fact that drug-target MR is a relatively novel tool in drug development, it holds great promise. When GWAS data is available, drug-target MR is a powerful tool for assessing target causality before drug candidates are entered into expensive clinical trial programs.
What’s more, this tool can provide must-needed evidence as to the clinical relevance of a novel drug target, which can make drug development decision-making more data driven. And by validating a drug target before further developing target compounds, late-stage clinical trial attrition could be greatly decreased.
But like any new tool, drug-target MR is not without its limitations.
Power is a particular challenge of the method, as illustrated by the fact that Dr. Tyl and his team were unable to find any functional variants for five of the nine sympathetic nervous system genes in their heart failure study. To overcome this limitation, the number of patients included in a GWAS could be increased, but this isn’t always feasible considering one of the large studies included in this program already had three-quarters of a million participants.
Whole-genome sequencing (WGS) can boost the number of common SNPs identified by two-fold; however, this approach is less useful for identifying rare, and ultra-rare, variants.
Another limitation of drug-target MR is the inability to distinguish between phenotypic effects in heart failure. In order to maximize power, the HERMES study included heart failure patients with varying values for ejection fraction. Just over half (54 percent) of patients included in the study had HFrEF, while 32 percent had HFpEF and 14 percent fell in the middle with HFmEF.
This increased study power comes at the cost of applicability and validity of results. Through this type of analysis, researchers are unable to say whether a drug target is specific to patients with HFrEF or HFpEF. And if a drug target is more relevant in one of these patient groups, the signal may be diluted due to the inclusion of other patient groups in the study.
Using Deep Clinical Data and WGS to Better Subtype Heart Failure Patients
Though the HERMES, and the related 2010 CHARGE study, performed large heart failure genomic association analysis, both consortia relied on genotyping and self-reported data. With a disease as heterogeneous and etiologically complex as heart failure, this design likely reduced the power of these studies, resulting in identification of fewer novel loci than the authors predicted.
According to Dr. Blat, the inclusion of deep clinical data from a variety of sources in studies is the answer to this power challenge. For example, good quality imaging data, such as that from a 2D echocardiogram, allows for the accurate subtyping of heart failure patients as HFpEF or HFrEF.
Longitudinal data is another important piece of deep clinical data that helps give a picture of the progression of heart failure over time. Biomarker measurements and other laboratory data can help support this long-term view of heart failure.
Comorbidities and cardiovascular disease risk factors help to further stratify patients beyond the labels of HFpEF and HFrEF, while surgical history helps put each patient group into context in terms of interventions they’ve received. Finally, outcomes data in the form of heart failure death and hospitalization records can provide a deeper understanding of the disease.
“We can use these different clinical measures to be able to subtype the patients based on the NYHA [New York Heart Association Functional Classification], or the American Heart Association (AHA) classifications,” says Blat, “but we can also use other approaches like unsupervised AI analysis to be able to predict what are the best measures that can classify these patients.”
By combining this deep clinical data with whole-genome sequencing data, researchers can capture more rare and low-frequency variants that may present with a higher effect size compared to using genotyping arrays. This approach also allows for the detection of variants outside of the coding region, boosting study power.
Genuity Science Drug Target Discovery Study
Using the combined power of deep clinical data and WGS, Blat explains the design for Genuity Science’s discovery of drug targets for HFpEF and HFrEF study. The goal is to recruit 11,000 heart failure participants with WGS data to the symptomatic heart failure cohort, the data from which will be compared to 20,000 population controls, 19,000 of which already have WGS data.
To start, the aim is to have an equal number of participants with HFrEF and HFpEF (5,000 for each), with the potential to include up to 10,000 patients with the latter. One thousand patients with HFmEF will also be included in the study.
An asymptomatic cohort of 1,400 participants with heart failure risk factors will be used to validate targets identified through the analysis of the larger symptomatic cohort. These asymptomatic patients have been followed for over a decade, with most patients developing asymptomatic HFpEF and HFrEF.
As this study is ongoing, Blat explains that the first interim analysis results will be available in Q2 of 2021, involving a total of 6,000 heart failure participants. Of this cohort, 4,700 patients have HFpEF, with the remaining 1,700 participants having HFrEF.
Some preliminary phenotypic data from the study shows an interesting distribution of comorbidities and heart failure symptoms among patients with heart failure (Figure 3).
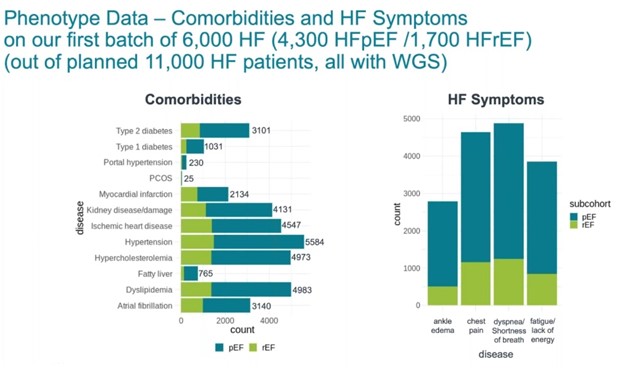
Figure 3: Comparison of phenotypic data from 6,000 heart failure participants with HFpEF and HFrEF involved in the Genuity Science study.
“We have the common co-morbidities that would predispose to heart failure, like hypertension, diabetes, myocardial infraction and others,” says Dr. Blat. “And these detailed heart failure symptoms, like edema and chest pain, shortness of breath and fatigue will also further allow us to determine the progression and the classification of these patients based on the NYHA and AHA guidelines for the different heart failure classes and stages.”
Biomarker data is another valuable source of information used by Genuity in this heart failure study. In particular, lab measurements of B-type natriuretic peptide (BNP), a biomarker for heart failure, helps to identify genetic variants associated with progression of heart failure (Figure 4).
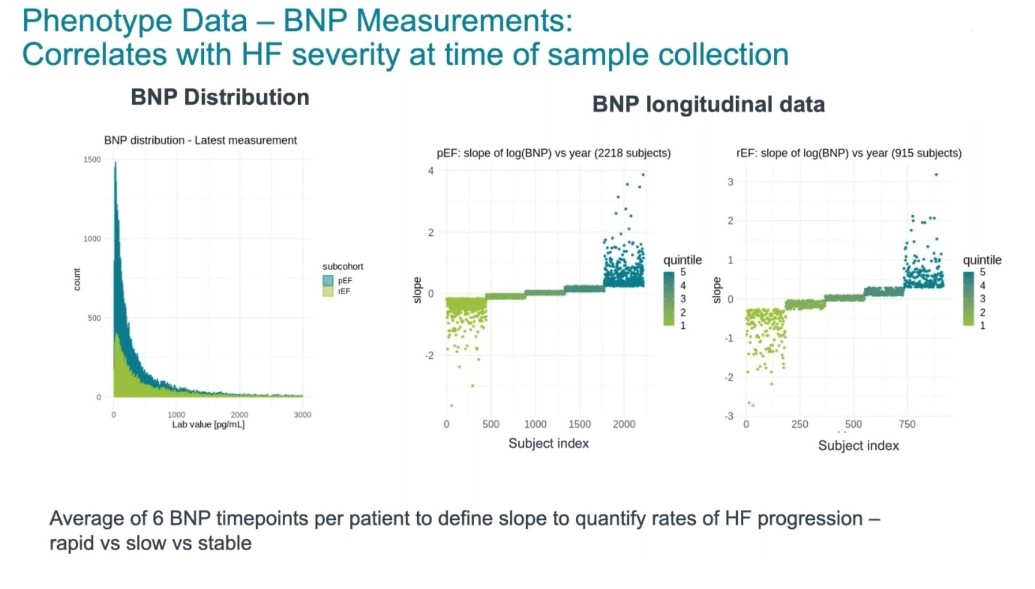
Figure 4: Distribution of BNP values for heart failure patients (left), and changes in BNP over time (right).
In order to stratify these patients further, they were split into two groups — those with preserved ejection fraction and those with reduced ejection fraction — and then categorized into quintiles based on their BNP measurements. With an average of six BNP measurements taken over time, the team were able to perform a correlation analysis to identify which variants were associated with rapid progression of heart failure, compared with slow progression and even stable and improved patients.
Deep echocardiographic data supports these other types of phenotypic data, and allows for participants to be characterized by disease severity.
And this approach isn’t just applicable to identification of disease-causing variants; the 1,400 patient cohort with asymptomatic heart failure involved in this study could allow Dr. Blat and her colleagues to identify protective variants.
“We have patients that are at stage A at baseline and follow-up that are over 70 years of age without echocardiographic evidence of heart failure,” says Dr. Blat. “This is really valuable in being able to identify or look at why these patients haven’t progressed, and if they have any variants that would protect them from developing this condition.”
A Better Approach to Drug Target Identification in HFpEF and HFrEF
In order to ensure an effective treatment for HFpEF is available one day, drug developers have to overcome a reliance on simple genotypic and self-reported data that isn’t useful when it comes to subtyping heart failure. Using deep clinical data and WGS sequencing, rare variants can be identified for which targeted drugs could be developed to treat the most therapeutically challenging forms of heart failure, such as HFpEF.
Genuity Science’s global cardiovascular disease datasets, combined with their cohort analytics platform, can help accelerate drug target identification in heart failure. To learn more about genomic advances in heart failure, watch their on-demand webinar.
This article was created in collaboration with the sponsoring company and the Xtalks editorial team.




Join or login to leave a comment
JOIN LOGIN