
Single cell sequencing has revolutionized the study of biological tissues and systems at the cellular and molecular level. Recent advances in the technology have allowed for the interrogation of distinct subsets of cell populations within tissues, and associated molecular markers that may function as important disease drivers.
The use of single cell sequencing in profiling bulk, heterogeneous tissues at the single cell level can help in the identification of dominant, unique and rare cell subtypes in a sample. Coupling single cell omics with other omics technologies and machine learning tools such as artificial intelligence (AI) can provide key insights about cellular and molecular targets that drive diseases. Characterization of disease pathways and systems can ultimately help lead to more effective disease treatment strategies such as cell-based and immunotherapies.
In recent webinars by Genuity Science, formerly known as WuXi NextCODE, experts from the biotech and pharma industries spoke about leveraging the power of single cell RNA sequencing platforms and solutions in conjunction with machine learning technologies such as AI in cell biology and disease research.
The Power of Single Cell Technology
In the last five years, significant strides have been made in the advancement of single cell technology and its use across different areas of biological research. Single cell RNA sequencing in particular has contributed the most to understanding the functional biology of a single cell in broader populations of cells, helping to highlight the presence of diverse cell populations within tissues and their distinct roles in disease.
In a webinar titled ‘Single Cell Sequencing: Transform Your Immunology and Cancer Research from Bulk to Single Cell Analysis,’ experts from Gilead Sciences, 10x Genomics and Genuity Science participated in an informative discussion on the power of single cell sequencing and analysis in transforming research in areas including immunology, cancer and cardiovascular disease.
Single cell RNA sequencing technology has been extensively applied to understand heterogeneity among tumor cells, within the tumor microenvironment and during cell development. The technology is also commonly used to conduct cellular subtyping, interrogate cellular functional states and elucidate cellular interactions. The detailed complexity of these processes can be captured by creating models that combine correlates of gene and protein expression, providing insight into the molecular composition of tissues.

Leading Innovations in Single Cell Technology
Rosha Poudyal, PhD, Science and Technology Advisor at 10x Genomics, discussed some of the innovative single cell technology tools that the company is developing and their application in various research areas including oncology, infectious disease and immunology.
Bulk cell analysis only allows for a single averaged data point, which averages out heterogeneity, making it difficult to detect rare and important cellular subtypes. Examining tissues at a single cell level makes it possible to capture different cell types and cell states within a sample, allowing for the interrogation of heterogeneity within a bulk cell population and detection of rare cell types, said Poudyal.
Chromium Single Cell Solutions
10x Genomics’ chromium single cell solutions are designed to accommodate a wide range of single cell or nuclei suspensions as a starting sample. These samples then undergo rapid and automated barcoding using the chromium controller to generate a high-throughput sequencing library. High quality open source software from the company can then be used to analyze and visualize the data.
In the barcoding process, the first sequence is a short universal PCR amplification sequence for sequencing the high-throughput sequencing library, followed by a barcode sequence. The barcode sequence is the same for all the oligos within a single gel bead, and each of the gel beads (shown in different colors in Figure 1) carries its own unique barcode sequence. The barcode sequence is followed by a unique molecular identifier, which enables accurate digital counting of gene transcripts. At the end is the poly(dT) sequence, which enables capturing of polyadenylated mRNA and prime it for cDNA synthesis, explained Poudyal.
Multimodal studies can be conducted with the addition of feature barcoding technology. Instead of the poly DT at the end of the sequence, a capture sequence can be added that enables capturing multiple analytes in addition to the transcriptome from the same cell (as they will all share the same 10x barcode). The technology can also be used for CRISPR guide screening or any feature of interest that can be captured via the use of the capture sequence.
Chromium Single Cell Immune Profiling Solution
The immune profiling solution from 10x Genomics allows for the characterization of multiple modalities from the same cell – these can include gene expression, T or B cell clonotypes (with full-length paired receptor sequence), cell surface marker expression and the capability to link T Cell Receptor (TCR) or B Cell Receptor (BCR) to antigen specificity.
The solution can also be used to assess functionality. For example, a high-resolution assessment of T or B cell activity at a single cell level can be made and frequencies of TCR clonotypes found within clusters can also be obtained (Figure 2, table on lower right).
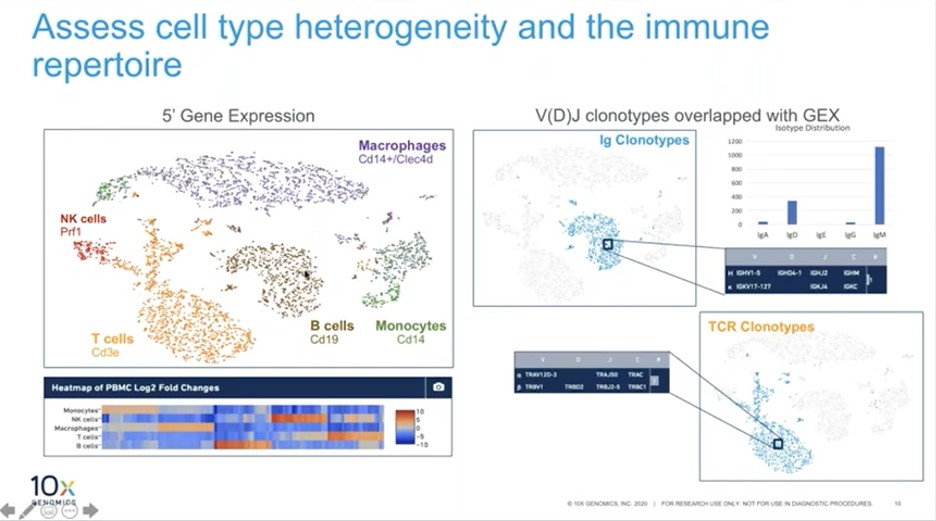
“In addition to providing high resolution, what we’re really striving to obtain is the multimodal data from the same cell. This application is a first example that can pave the way to a complete and comprehensive immune profiling,” said Poudyal.
Spatial Transcriptomics
The study of disease models and answering fundamental questions in biology is greatly enriched by high-resolution, single cell studies that enable multi omics approaches. “Now with spatial technologies, you can start adding spatial context to your molecular data for a comprehensive view of biology,” said Poudyal.
Tissue spatial context is very important when studying diseases such as cancer where information on the localization of tumor infiltrating lymphocytes (TIL), for example, is important in informing treatment and prognosis. However, in traditional single cell experiments, tissue is dissociated into single cell suspensions, and thus the context of where TILs were located in the original tumor specimen would be lost. Coupling single cell experiments with spatial transcriptomics is an ideal solution for maintaining and studying biological spatial context that has important clinical value.
Visium Spatial Gene Expression Solution
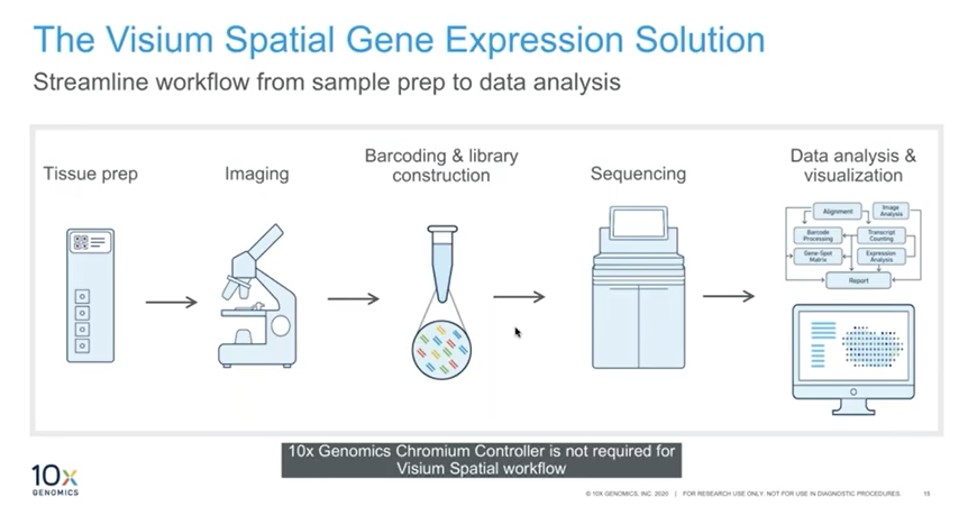
To address challenges associated with loss of spatial context, 10x Genomics has developed the Visium Spatial Gene Expression solution, which enables answering biological questions in the context of tissue using an unbiased gene expression approach. Its multimodal approach involves coupling gene expression information with histological staining of tissue samples.
On Visium Gene Expression slides, there are areas called capture areas, which have a lawn of barcode on them. Tissue sections are put on the slide capture area and H&E stained, followed by imaging. cDNA can be generated on the same slide utilizing the barcoded oligos – in this way, the cDNA is barcoded with a spatial coordinate barcode. After acquiring the sequencing data, the unbiased whole transcriptome data is overlaid onto the H&E image to obtain the spatial context (Figure 3).
Visium can be used in an unbiased discovery approach. Spatially naïve clustering can be performed with no spatial awareness, which is an unbiased way of analyzing data.
Applications of Single Cell Sequencing in Virology Research
Jeffrey Wallin, PhD, Senior Director Biomarkers at Gilead Sciences discussed the use of single cell sequencing to support virology programs at Gilead. He specifically presented clinical data from a Hepatitis B study where peripheral T cell clones were followed in response to a specific treatment.
The approaches for virology programs involve RNA seq and single cell RNA seq for gene expression profiles to identify and phenotype cell populations. TCR seq and BCR seq are used for T cell and B cell clone quantification and phenotyping, respectively, and it is quite useful to combine these techniques and look at gene expression within TCR and BCR clones, said Wallin.
Single Cell Data Analysis
Single cell sequencing provides very rich datasets that can be analyzed in-depth using biocomputational approaches.
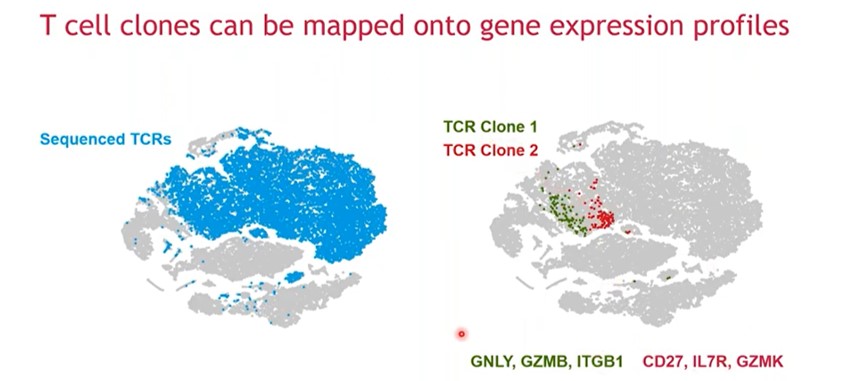
Gene expression profiles can help identify different clusters of cells, and high-resolution analysis can help identify distinct immune cell populations such as monocytes, B cells and K cells, as well as different subpopulations of T cells such as CD4 positive T cells and CD8 positive T cells.
These cellular subsets can be further characterized based on expression levels of molecular markers such as enzyme expression (i.e. enzymes such as perforin and granzymes) that are important to their effector function. For example, CD8 positive T cells that express perforin and granzymes form a distinct cluster compared to cells that are negative for the enzymes. In this way, cellular subpopulations can be more extensively phenotyped. TCRs can also be sequenced in the same cells to identify individual TCR-based clones (Figure 4). In the t-SNE plots on the right in the figure, green and red are the top two clones within the dataset and they both fall within the group of CD8 positive T cells. The two different TCR clones map to different areas in the plot, and while they are close to each other, they do not overlap and differentially expressed genes between the two clones can be identified.
Single cell approaches can also be used to evaluate cellular responses to peptide inhibitors or other therapeutic drugs. Cells can be treated with an inhibitor and its effect on the expansion of particular antigen specific cells can be evaluated by single cell RNA seq, followed by TCR seq to specifically evaluate T cell populations in the expanded cultures, for example. Combining this with gene expression profiles, specific subsets of cell be identified. For example, in a CD4 positive T cell set, naïve CD4 positive T cells can be differentiated from different memory populations such as central vs. effector memory cells.
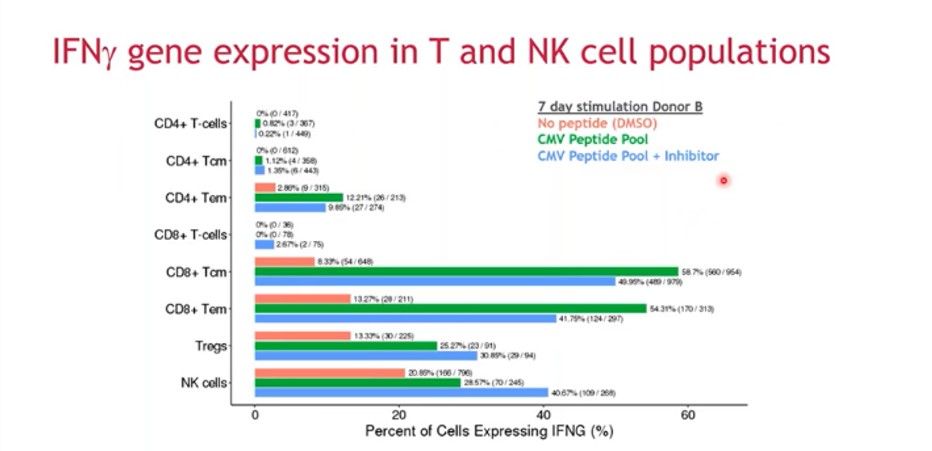
More specific questions can then be asked about the cell populations, including functional information. For example, re-stimulation of cultured cells can lead to expression of interferon (IFN)-γ and other important cytokines associated with T cell function. In Figure 5, it can be seen that a CMV peptide increases the percentage of cells expressing IFNγ in the presence or absence of an inhibitor, especially in memory cell populations.
Using single cell sequencing, peripheral blood mononuclear cells (PBMCs) and associated tissues can be evaluated at high resolution. Changes in different cell populations and phenotypes, such as T and B cell clones, can be traced in treatment studies. This level of detail about the evolution and expansion of different clonotypes during the course of disease or treatment is extremely informative and can help in the understanding of disease biology, and in guiding treatment options.
Combining Single Cell Analysis with Machine Learning and AI
In a webinar on applications of single cell analysis in combination with statistical machine learning technologies such as AI, scientific and data science experts discussed the application of single cell analysis with machine learning in the development of cell and gene therapeutics.
Profiling Disease Targets for Clinical Utility
Robert Deans, PhD, CSO at Synthego discussed his experience building ex vivo cell therapeutics at Blue Rock Therapeutics, where he worked prior to joining Synthego. There is great value in single cell interrogation in the clinic al setting either directly in situ, or in modeling human disease, said Deans.
Deans explained “how the ability to interrogate the transcriptional profile of the products produced was highly informative both from a development and regulatory context in building analytics and assays needed to confirm potency and final product, but also in being able to develop a genetic node-based developmentally driven process for expansion of our desired product.”
Deans’ work involved the characterization of cell products produced from induced pluripotent stem cell (iPSC) sources. Through the application of single cell transcriptomics across a 21-day stage bioprocess, a normal developmental biological map for cell differentiation was constructed. The developmental map was recapitulated by overlaying analysis that incorporates developmentally staged genes and understanding that the subsets that emerge from the population recapitulate that biology, said Deans.
Through single cell transcriptomics, different cell clusters can be identified in a population. Applying a temporal component across that can allow for the determination of which clusters appear early on and which occur late, and interrogating clusters individually can help identify sets of genes which characterize that population. For example, in Figure 6, neuronal progenitors can be seen to move through the blast stage and through to final maturation across the process.
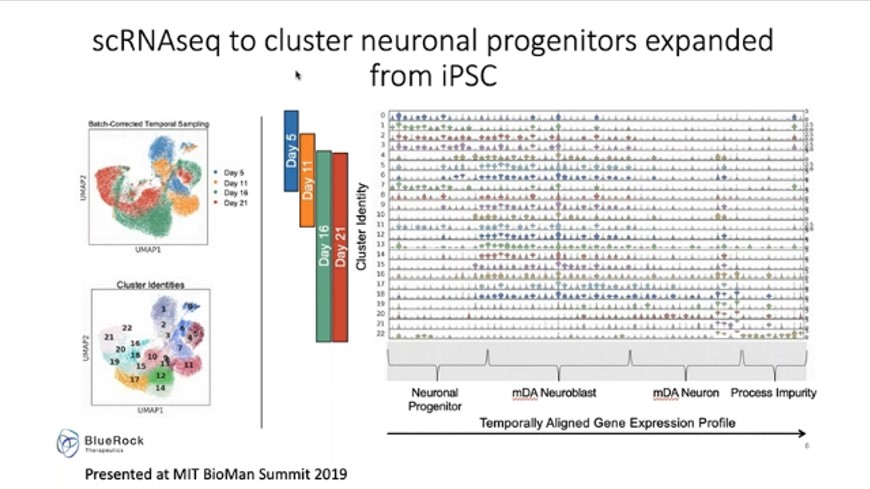
One of the other utilities is to use the information to build a potency assay for a product, explained Deans. By taking the composition of the final product and comparing it to other compositions from your own work and the work of other investigators, Deans said that can be overlaid on outcome. “Now you have a predictive outcome that can be gleaned from this type of single cell RNA seq analysis and that can be deconvoluted to give you very important information about the active pathways and the potency of your final product.”
This approach can also be applied in situ so that you can move from analysis to a pre-clinical model in which the donor population can be interrogated and compared to the recipient – this can allow for active disease modeling in situ at the single cell level.
Single Cell Analysis and Drug Discovery
Gregory Ryslik, PhD, FCAS, MAAA, Chief Data Officer at Celsius Therapeutics discussed the use of single cell analytics in the context of drug discovery.
Celsius Therapeutics is a precision medicine company whose goal is to develop therapeutics that do not currently exist for diseases such as cancers or autoimmune diseases that do not have any druggable driver mutation. In order to do this, the company is developing a differentiated understanding of these diseases via single cell genomics and machine learning.
In cancers that do not have druggable driver mutations or in inflammatory bowel disease where there isn’t a good of understanding of disease biology, single cell genomics can help in the understanding of what is happening at the cellular level, and mine datasets to find biological signals and targets, explained Ryslik.
The company’s drug discovery approach with human samples involves three steps: perform single cell RNA sequencing, identify cell types that may differ between healthy and diseased or inflamed and uninflamed tissue, determine differentially expressed genes using a variety of techniques including some that are custom built and then visualization using t-SNE plots. Importantly, the data is integrated with orthogonal datasets such as GWAS data or data generated from functional genomics. Because human samples are used, there’s a direct path to the identification of patient subsets for which we might be able to create drug targets, said Ryslik.
Single Cell Omics and Computational Analysis
On the computational side, there are two major components: one is the data engineering piece and the other is the AI piece. Ryslik said, “I think AI just as a terminology has been vastly overused, so when I say AI, I mean good statistics and mathematics with proper computer science and coding.”
On the data engineering side, Celsius has “built a pipeline that does everything in the cloud from quality control to event detection to differential expression to t-SNE plotting, all from start to finish in about five hours regardless of how many samples we need to process because the number of machines will just scale,” explained Ryslik.
On the machine learning AI side, cell type calling and novel cell type detection can be performed, beginning with data cleaning, analysis, quality control and visualizations, along with the use of more advanced methods to help find novel insights. Transfer learning is also used to take information obtained from signatures from human cells to develop a working animal model. This kind of an integrated approach can allow for robust disease profiling and modeling.
“At the end, it is all about the samples and every sample added sample improves signature scores, allowing for more accurate cell type classification, which is looped into the database and restarts the cycle,” said Ryslik. This has allowed Celsius to begin building an in-house ‘human cell atlas of disease,’ which allows comparison of healthy cells vs. diseased/inflamed cells with identification of unique cell types and the potential drivers for them.
The Power of Single Cell Omics in Drug Development
Thomas W Chittenden, PhD, DPhil, PStat, Chief Data Science Officer at Genuity Science, spoke about the power of single cell analysis and believes that it can truly transform the healthcare industry.
He explained that as a contract genomics organization, the company works closely, or partners with, the pharmaceutical industry to help big pharma develop more efficacious drugs.
He discussed the role of single cell analysis in drug development saying, “I believe that the most important aspect of any drug development pipeline starts with the identification of what we refer to as causal drug targets. If you can hit that mechanism of action, the disease etiology, hit that nail right on the head, then inevitably you are going to be able to develop more efficacious therapeutics with much [fewer] side effects.”
AI machine learning tools have come a long way and are “actually capable of informing, teaching and advancing our current understanding of the molecular constituents that drive cellular behavior and dictate phenotype,” said Chittenden. “And we have direct evidence now that we have integrated probabilistic programming within all of our classification models, so we are actually capable of deriving causal dependency structures that are actually reflective of the signal transduction cascades that occur in the cell, which I believe in itself is going to be transformative,” he said.
Chittenden shared some experiences around bulk RNA and probabilistic programming or causal inference and how it can be integrated to derive or uncover drivers of disease.
Identification of Causal Disease Drivers
Chittenden and colleagues published a paper in the Journal of Experimental Medicine in 2019 in collaboration with Professor Michael Simons at the Yale School of Medicine in which they conducted a study to examine ERK1/2 as being a possible downstream effector in TGF-β signaling in vascular inflammation and atherosclerosis. For this, the company designed an in silico phenotype projection model, analogous to reverse genetics, which was experimentally validated within six months.
Simons perturbed the ERK1/2 genes in human cells and Chittenden put it through a bulk RNA seq pipeline, which involved a combination of deep learning and machine learning. Through this approach, they were able to derive a causal dependency structure, which was then validated.
Figure 7 depicts a network analysis of cellular differentiation in aortic aneurysm. The analysis produced a single vector cell differentiation model that was used to build a molecular road map for the disease state. Based on the preliminary results, it appears that the aneurysm is a three vector disease.
In the model, an aberrant cell cluster was identified in the thoracic region. Casual dependency structures were built and from this, a specific gene was shown to be implicated, which is a known driver of calcification, ossification, inflammation and cell differentiation. It also shows that cell differentiation is driving the aberrancy of this average cell cluster. This information would not be decipherable through bulk RNA seq approaches as critical timepoint information would be lost by averaging the results.
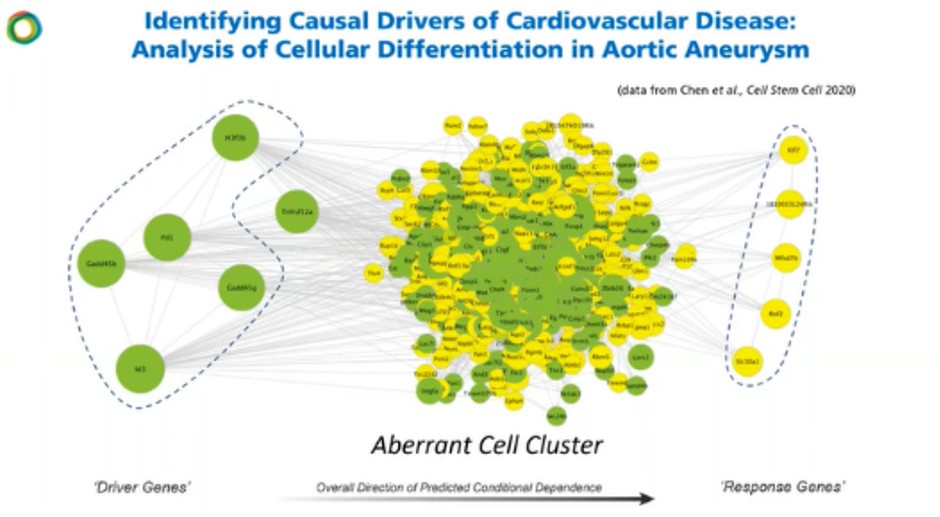
This kind of molecular disease modeling arms researchers with the information they need to go after in experimental models at the lab bench.
Driving the Future with Single Cell Omics and Computational Learning
Combing the high resolution of single cell sequencing with statistical machine learning and AI tools paves the way for a new age of discovery science from a research and development standpoint for the development of efficacious therapeutics. The combination of these detailed approaches can further our understanding of human disease biology at the cellular and molecular level to identify functional targets that can guide therapeutic drug development.
To learn more about the application of machine learning in single cell omics, register to watch the free webinars titled ‘Single Cell Sequencing: Transform Your Immunology and Cancer Research from Bulk to Single Cell Analysis’ and ‘Recent Success Combining Single Cell Sequencing with AI/Advanced Analytics.’
This article was created in collaboration with the sponsoring company and the Xtalks editorial team.





Join or login to leave a comment
JOIN LOGIN